
HTTP는 응용 계층 프로토콜로 클라이언트와 서버로 나누어져 동작하는데, 클라이언트는 사용자, 웹 브라우저 쪽으로 웹에서 필요한 것들을 서버에 요청/수신/표시한다.
서버는 클라이언트의 요청에 대한 응답으로 클라이언트가 필요한 객체를 보내준다
HTTP는 안정적인 전송이 가능한 TCP를 사용하는데, 이 TCP로 클라이언트와 연결을 맺는다.
클라이언트가 80번 포트(HTTP는 80번 포트 사용)를 통한 TCP 연결을 생성하고 서버가 이 연결을 승인하면, 브라우저와 웹 서버, 즉 클라이언트와 서버가 필요한 HTTP 메시지를 교환하고, 교환이 완료되면 연결을 종료하는 과정으로 통신이 이루어진다.
이때, 서버의 부담을 줄이기 위하여, 서버는 과거에 있었던 요청에 대한 정보를 유지 및 관리하지 않고, 사용자에 대한 정보를 저장하고 싶은데, HTTP의 이러한 특성 때문에 하지 못했던 것을 뒤에 나온 쿠키를 사용해 해결 및 구현한다.

위에서 설명했던 통신 방식을 예시를 들며 더 자세하게 설명한 내용이다.
www.9coding.com/index라는 가상의 사이트가 있다고 할 때, 여기서 텍스트와 이미지를 불러오는 요청을 한다고 해보자.
클라이언트는 80번 포트에서 HTTP 서버에 TCP 연결을 시작하고, 호스트의 HTTP 서버가 80번 포트에서 TCP 연결을 기다린다.
HTTP 클라이언트는 index를 원한다는 내용의 URL 포함 HTTP 요청 메시지를 TCP 연결 소켓으로 전송한다.
서버는 요청 메시지를 수신하여, 그 요청하는 개체를 포함하는 메시지를 형성하고 소켓으로 전송한다.
그 후에, HTTP 서버는 TCP 연결을 종료하고,
클라이언트는 html 파일이 포함된 응답 메시지를 수신하고, html을 표시하고, 구문 분석과 이미지 찾기를 수행한다.
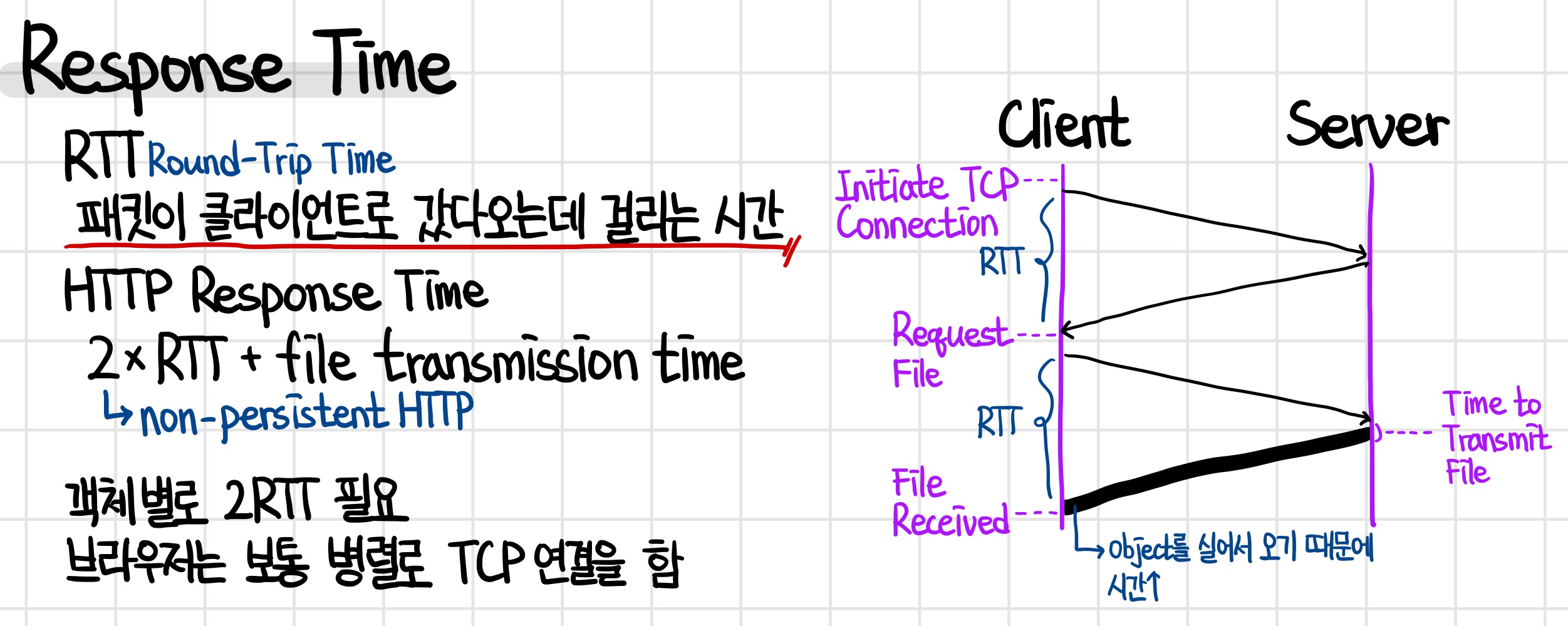
Response Time(응답 시간)에 관하여 알아보자. 응답 시간을 알아내기 위해서는 RTT, Round-Trip Time을 알아야 한다.
RTT란 패킷이 클라이언트로 갔다 오는데 걸리는 시간으로, 클라이언트에서 출발하여 서버에 도착했다 출발해 클라이언트에 다시 돌아오면 1RTT이다.
HTTP의 응답시간은 non-persistent HTTP일 때 2xRTT + file transmission time으로, 2번의 RTT가 걸린다.
옆의 그림을 보면, 초기엔 클라이언트가 TCP 연결을 만들기 위해서 서버에 다녀온다. 연결이 승인되었으면, 파일을 요청하기 위해 서버를 다녀온다.
이때, 가장 마지막 선은 굵게 표시되어 있는데, 이는 메시지를 포함한 실제 object를 포함하여 서버에서부터 클라이언트로 오기 때문에 파일을 옮기는 표시한 것이다. 이 굵은 부분이 file transmission time이다.
이런 방식을 쓰면, 가져오려는 객체마다 2RTT가 필요하다.

이렇게 개체 별로 2RTT + file transmission time이 필요한 Non-persistent HTTP를 개선한 것이 Persistent HTTP이다.
일단 Non-persistent 방식에 대해 알아보면, 연결을 생성한 후에 객체를 받고 연결을 종료하는 방식으로, 연결 한 번에 하나의 객체를 받게 된다.
그래서 object 마다 2RTT + transmission time이 필요하다. 따라서 개체 다운로드 수가 많아질 수록 연결도 많아지는 비효율적인 문제가 발생하게 되는데,
Persistent HTTP는 응답을 보낸 후에도 TCP 연결을 유지하여 한 번의 TCP 연결로 여러 객체를 전송할 수 있다.
클라이언트가 참조된 개체, 즉 이미 연결된 TCP를 발견하면 요청을 보낸다.
그런데 TCP 연결을 계속 열어놓으면 자원 낭비가 발생할 수 있으니 적절한 시간 후에 끊어주는 것이 좋다.
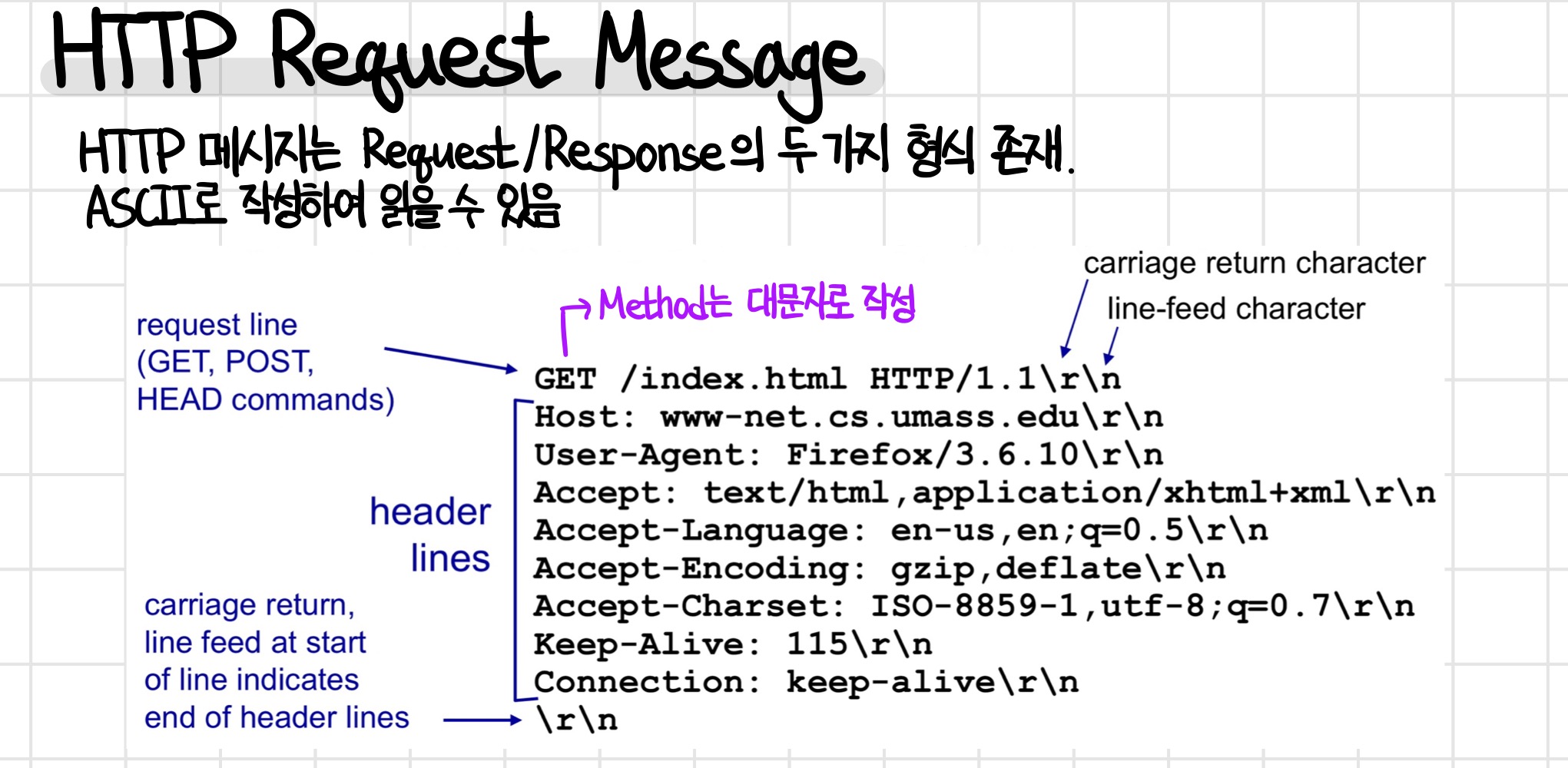
HTTP 메시지는 요청과 응답의 두 가지 형식이 존재하는데, 아스키 코드로 작성되어 읽을 수 있다.
메시지를 간단히 살펴보면 처음에는 GET, POST, HEAD 등의 메소드가 입력되고, (이때 메소드는 반드시 대문자로 작성되어야 함)
요청하는 페이지, 버전 등이 첫 줄에 적혀있는 것을 볼 수 있고, 그 아래 header lines가 존재하는 것을 알 수 있다.

HTTP 요청 메시지의 첫번째 자리에 위치하는 메소드는 GET/POST/HEAD/PUT/DELETE 등이 있는데,
GET은 서버에서 어떤 데이터를 조회하여 보여줄 때 사용하고,
POST는 주로 자원을 생성하기 위한 데이터를 생성한다.
HEAD는 데이터의 header 정보를 요청할 때 사용한다.
PUT은 자원을 생성하거나 수정하기 위해 서버에 데이터를 전송하고,
DELETE는 지정된 자원을 삭제한다.
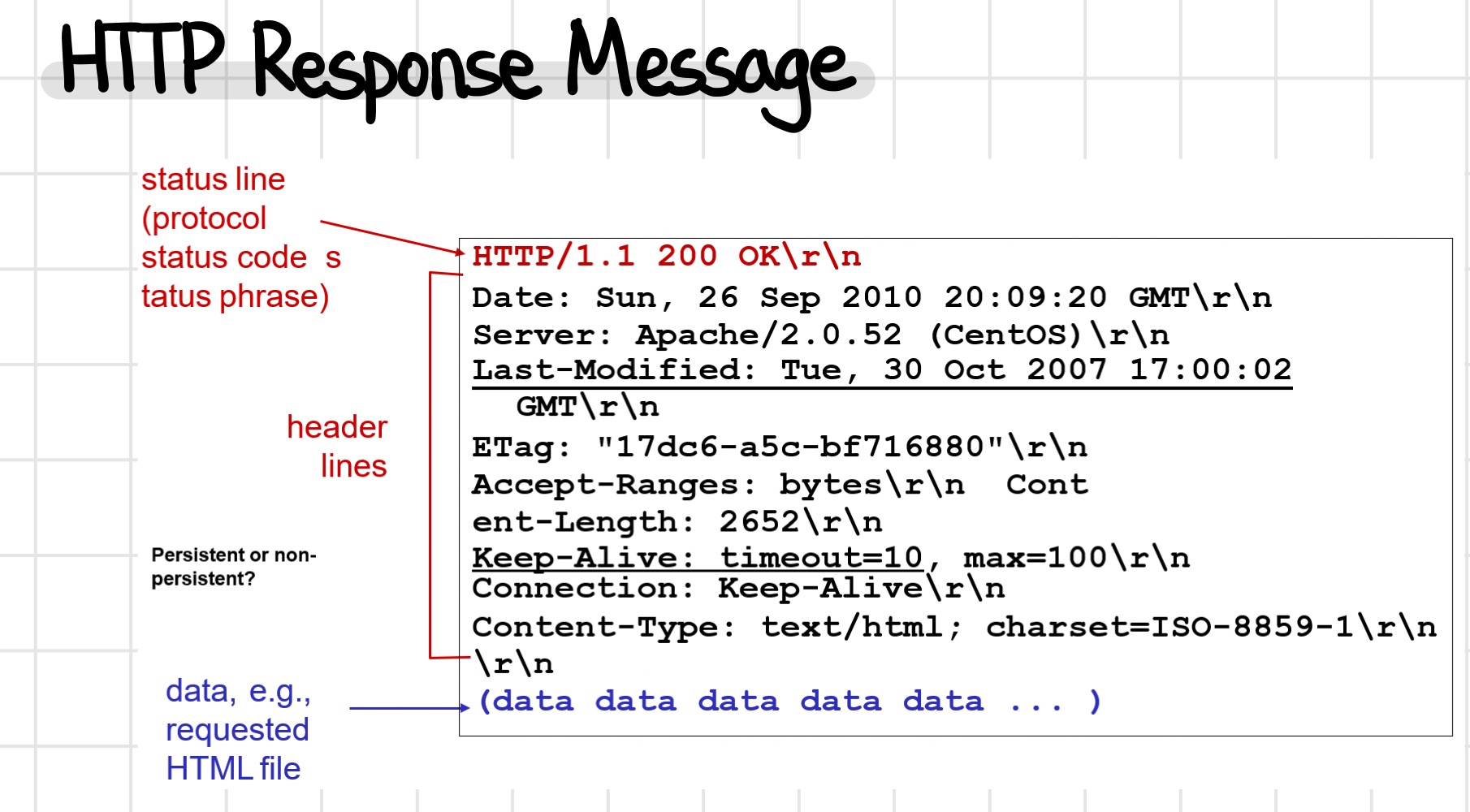
HTTP 응답 메시지는 다음과 같이 생겼고, 첫 줄의 status line 중 자주 사용되는 몇 가지를 소개하자면,
200 OK : 요청 성공.
301 Moved Permanently : 요청한 개체가 이 메시지의 뒷부분에 지정된 새 위치로 이동.
400 Bad Request : 요청 메시지를 서버에서 이해할 수 없음.
404 Not Found : 요청한 문서를 서버에서 찾을 수 없음.
505 HTTP Version Not Supported

쿠키는 앞서 잠깐 소개했듯 사용자의 정보를 기록하고 싶은데, 과거의 요청을 기록하지 않는 HTTP 때문에 사용하게 되었다.
(어떤 웹사이트에 방문했을 때 ‘쿠키를 허용하시겠습니까?’ 할 때의 그 쿠키다)
쿠키가 사용되는 예시에는
1. HTTP 응답 메시지의 cookie header line
2. 다음 HTTP 요청 메시지의 cookie header line
3. 브라우저 관리 및 유저 호스트에 보관되는 쿠키 파일
4. 웹 사이트의 백엔드 DB 등이 있다.
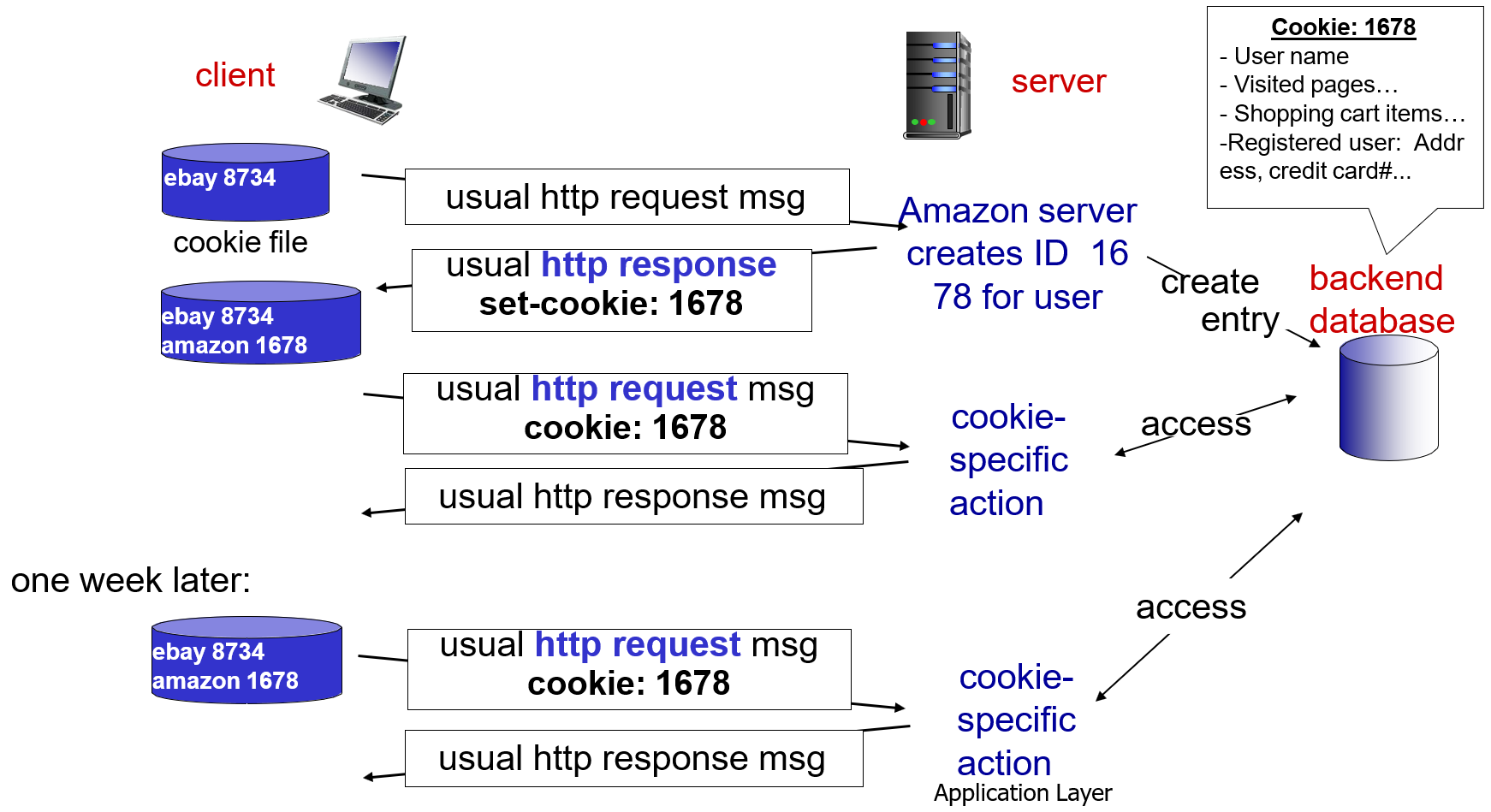
이는 쿠키가 실제 동작하는 예시이다.
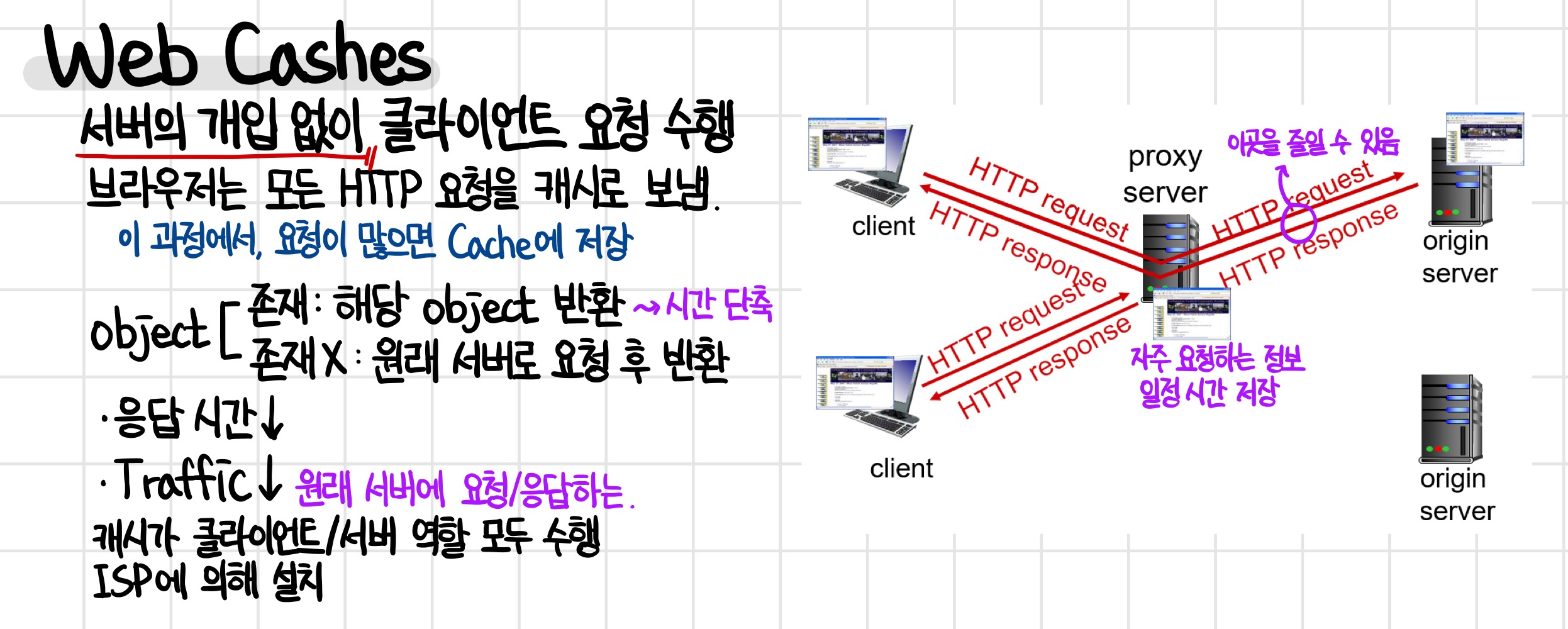
웹 캐시는 cpu의 캐시와 비슷한 느낌인데, 서버의 개입 없이 클라이언트의 요청을 수행할 수 있는 프록시 서버를 운영하면서 사용할 수 있다.
브라우저는 모든 HTTP 요청을 캐시로 보내는데, 이때 특정 요청이 많으면 그 요청에 대한 정보를 일정 기간 동안 캐시에 저장한다.
다른 요청이 발생했을 때, 그 요청이 프록시 서버에 존재하면 해당 개체를 반환하고, 존재하지 않으면 원래 서버에 요청한 후 받은 값을 반환한다.
옆의 사진을 보면 클라이언트와 기존 서버 사이에 프록시 서버가 위치하는데, 여기에 자주 요청하는 정보를 넣어놓고, 클라이언트에서 기존 서버에서 가는 거리를 프록시 서버가 줄여줌으로써 시간을 단축시킬 수 있다.
따라서, 시간 뿐만 아니라 원래 서버에 요청 및 응답하는 Traffic도 효과적으로 줄일 수 있게 된다.
ISP에 의해 설치되며, 캐시는 클라이언트와 서버의 역할을 모두 수행한다 (클라이언트와 서버 사이에 위치하므로)


'네트워크 > Application Layer' 카테고리의 다른 글
| [네트워크] Application Layer (1) (0) | 2022.10.18 |
|---|