Transformer를 sequences of image patches에 직접 적용해도 classification에서 뛰어난 성능을 보임!
특징
- NLP에서 사용되는 Transformer를 Vision Task에 적용
- CNN구조 대부분을 Transformer로 대체 (입력단인 Sequences of Image Patch에서만 제외)
- 대용량 데이터셋 Pre-Train → Small Image 데이터셋에서 Transfer Learning
- 훨씬 적은 계산 리소스로, 우수한 결과를 얻음
- 단, 많은 데이터를 사전 학습해야 된다는 제한사항 있음
이미지를 patch의 sequence로 해석한 뒤, NLP에서 사용되는 표준 Transformer 인코더로 처리
- 단순, 확장 가능, 대규모 데이터셋으로 사전 학습 → 좋은 성능
- SOTA와 동등하거나 초과하는 결과를 내면서 상대적으로 저렴한 pre-training 가능
데이터가 적은 경우는 ResNet보다 성능이 떨어짐
- Translation과 locality 같은 Inductive bias가 부족.
- translation equivariance 부족
- 불충분한 데이터 양으로 generalize가 잘 안 됨.
(related work 생략)
Inductive Bias
ViT는 CNN보다 image-specific한 Inductive Bias가 약하다.
Inductive Bias: 만나지 못한 상황을 해결하기 위해 추가적인 가정을 활용하여 문제를 해결.
- 가정에서 벗어나는 경우 예측력 떨어짐.
- ex) CNN은 locality라는 가정을 활용하여 spatial 문제를 풀고, RNN은 sequentiality라는 가정을 활용하여 Time-series 문제 해결.
CNN
- Locality
- 이미지를 구성하는 특징들은 전체가 아닌 일부 지역들의 픽셀들로만 구성되고 이들끼리만 종속성을 갖는다는 가정. - Two-Dimensional Neighborhood Structure
- Translation Equivariance
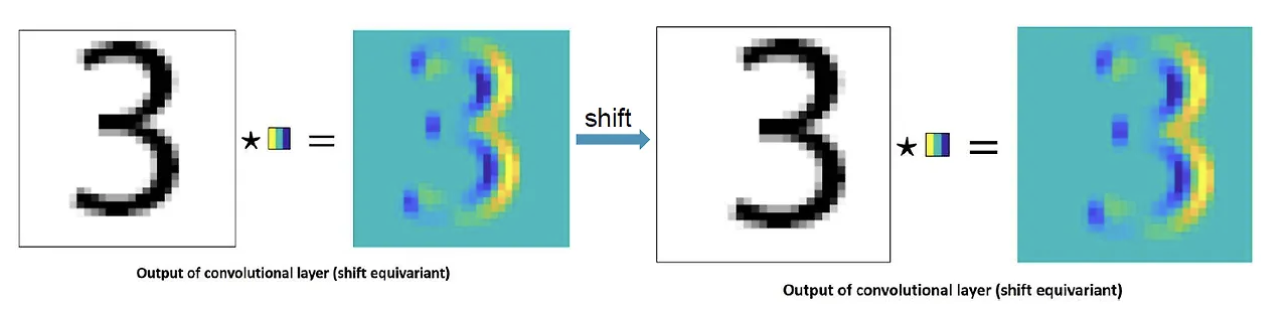
- 입력의 위치 변화에 따라 출력 또한 입력과 동일하게 변화하는 것
- 이들이 model 전반에 걸쳐 모든 계층에 내재되어 있음.
ViT
- MLP layer에서만 Locality, Translation Equivariance.
- self-attention layer는 global로 동작.
- Two-Dimensional Neighborhood Structure: 아래 상황에서 제한적으로 사용.
- 학습: 모델 시작 단계에서 이미지를 patch로 나눌 때
- fine-tuning: 다른 resolution 이미지에 대해 position embedding을 조정할 때 - ViT가 Inductive Bias가 부족한 이유&극복Fully connected 방식은 픽셀에 대한 가중치로 연산을 하므로 translation equivariance 감소.
- ViT에서는 MLP에서는 각 패치가 무얼 의미하는지에 대한 정보를 추출하도록 하고 이 정보를 기반으로 MSA에서 각 패치들과의 연관성을 고려하도록 하면서 이러한 단점을 극복하도록 합니다.
- 이미지를 패치로 나누고, MLP는 한 패치 내부에서만 작동.
이러한 특징들로 인하여 큰 데이터셋에서는 강력한 성능을, 작은 데이터셋에서는 일반화 어려움을 갖는다.
Hybrid Architecture
입력을 raw image patch 대신 CNN feature map으로 대체 가능
이를 활용한 hybrid model에서는 CNN 특징 맵으로부터 패치를 추출한 후, 패치 임베딩 적용.
- CNN의 특징 추출 능력을 활용하면서, Transformer의 강력한 시퀀스 처리 능력을 결합한 접근 방식
- CNN의 inductive bias를 활용하면서 Transformer의 전역적 학습 능력을 도입하는 방법
- 다양한 상황에서 성능을 향상시킬 수 있다.
주요 특징
- 하이브리드 입력 구조:
- CNN으로부터 생성된 특징 맵에서 패치를 추출.
- 각 패치에 대해 선형 투영(linear projection)을 적용하여 Transformer 차원으로 매핑. - 특별한 경우 (1x1 패치):
- 패치 크기가 1×1인 경우, CNN feature map의 spatial dimensions을 단순히 flatten한 뒤 Transformer 차원으로 투영한다.
- 이는 CNN 특징 맵 자체를 Transformer의 입력 시퀀스로 변환하는 간단한 방식이다. - 위치 및 분류 임베딩 추가:
- classification input embedding과 position embedding을 입력 시퀀스에 추가한다.
Fine-tuning and Higher-resolution
사전 훈련 때보다 더 높은 해상도로 Fine-Tune 하는 것이 성능에 도움이 됨
pre-trained prediction head를 제거하고 0으로 초기화된 $D \times K$ feedforward layer를 붙임.
- $K$: downstream class 개수
Patch 크기 고정
- fine-tuning시 입력 이미지 resolution 증가
- 패치 크기를 고정하면 개수가 증가해 더 긴 시퀀스 생성.
- 더 높은 해상도 & Patch Size 동일 → Sequence 길이 증가
2D Interpolation
- resolution이 바뀌면 sequence 길이도 변하므로 기존 pre-trained position embeddings 유효X.
- 새로운 resolution에 맞춰 2D Interpolation 수행
- 원본 이미지에서의 patch 위치에 따라 pre-trained position embeddings 값을 새 resolution에 맞게 조정.
- Inductive bias를 추가할 수 있게 됨.
대형 데이터셋에서 학습을 시키고, fine-tuning 과정에서 2D interpolation을 진행해 inductive bias를 활성화시켜주어 더 높은 성능을 달성할 수 있었던 것으로 보임.
Method

Input
image를 patch로 분할해 linear embedding의 sequence를 transformer의 input으로 사용.
Image Patch: NLP에서의 token(words)과 같음.
Embeddings
2D image를 기존의 token처럼 활용하기 위해 1차원으로 변환하는 작업.
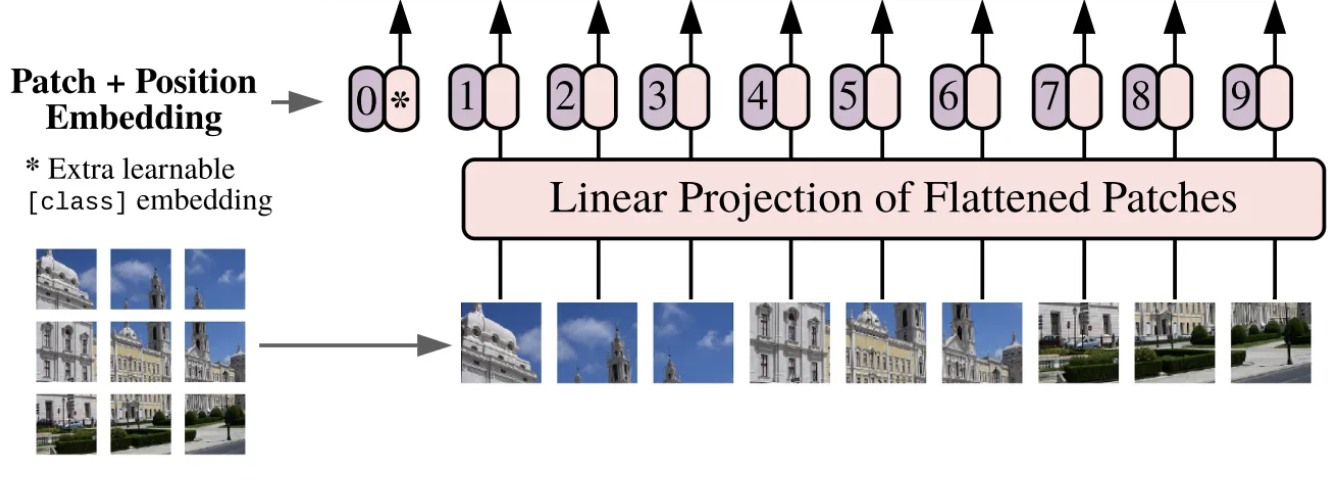
Patch Embedding
하나의 이미지를 여러 패치로 나누어 인코더의 입력 시퀀스로 삽입.
image $x \in \mathbb R^{H \times W \times C}$를 sequence of flattened 2D patches $x_p \in \mathbb R^{N \times (P^2 \cdot C)}$로 reshape.
- $(H, W)$: 원본 이미지의 resolution.
- $C$: channel 수
- $(P, P)$: 각 image patch의 resolution
- $N=HW/P^2$: 생성된 patch의 수. Transformer의 effective input sequence length로 사용.
- $D$: constant latent vector size.
- image patch를 flatten하고, 학습 가능한 linear projection을 통해 $D$ dimensions로 매핑
- 이 projection의 출력: patch embeddings.
- Ex)
- 이미지 크기가 $H=W=224$이고 $P=16$일때 $224\times224 / 16^2 = 196$개의 $16×16×3=768$ 차원의 텐서로 이루어진 시퀀스.
- 시퀀스의 각 요소 별로 임베딩을 위한 선형변환을 수행하고 (patch embedding) 모델 전체의 차원은 D로 통일.
- $H=W=224,P=16$인 경우, patch embedding 결과 $196×768$ 크기의 패치 임베딩 행렬 도출
learnable embedding
learnable embedding을 patch embedding sequence의 앞에 추가
- BERT의 class token과 유사.
- 추후 이미지 전체에 대한 표현을 나타내게 됨.
- MLP Head에 입력으로 들어가 classification 작업에 사용됨.
- $z^0_0 = x_{\text{class}}$로 정의.
- $z^0_L$: 최종 L번째 layer의 0번째 token에 대응.
Position Embedding
시퀀스 각 요소의 위치 정보를 알려주기 위한 방법.
$\text E_{\text {pos}} ∈ \mathbb R^{(N+1)×D}$: Position Embeddings
- 초기에는 patch의 2D 위치에 대한 정보 포함X
- patch 간 모든 spatial relations는 학습을 통해 처음부터 습득해야 함.
- Ex)
- 위의 예시에서, class token을 위한 임베딩은 $1 \times 768$ 크기의 벡터.
- 이것이 패치 임베딩 행렬 왼쪽에 붙어
- 최종적으로 $(196+1) \times 768$ 크기의 텐서
Linear Projection
$z_0 = [x_{\text{class}}; x^1_p\text E; \; x^2_p\text E; \; ··· ; x^N_p\text E; \;] + \text E_{\text {pos}}$
- $\text E ∈ \mathbb R^{(P^2·C)×D}$: Patch Embeddings
- $\text E_{\text {pos}} ∈ \mathbb R^{(N+1)×D}$: Position Embeddings
Patch embedding에 position embedding을 추가해 위치 정보를 보존한다.
일반적으로 학습 가능한 1D 위치 임베딩을 사용
이렇게 생성된 임베딩 벡터의 시퀀스가 인코더의 입력으로 사용된다.
Transformer Encoder

기존 transformer의 encoder 부분을 변경하여 사용.
MSA 층과 MLP 블록이 번갈아 가며 배치.
- LN: LayerNorm. 모든 블록의 입력에 적용.
- Residual connections: 각 블록의 출력 뒤에 추가
MSA
Multi-Headed Self-Attention.
$z’l = \text {MSA}( \text {LN}(z{l-1})) + z_{l-1}$
- 입력에 LayerNorm 적용 → MSA 연산 → 결과 residual connection으로 합산.
MLP
두 개의 층으로 구성되며, activation function으로 GELU 사용
$z_l = \text {MLP}( \text {LN}(z'_l)) + z'_l$
- 입력에 LayerNorm 적용 → MLP 연산 → 결과 residual connection으로 합산.
최종 출력
$y = LN(z^0_L)$: 인코더의 출력에서 해당 임베딩의 상태 $z^0_L$이 이미지 표현 y로 사용.
- pre-training, fine-tuning 단계 모두에서, $z^0_L$에 classification head 연결.
- pre-training: 1개의 hidden layer를 가진 MLP로 구현.
- fine-tuning: single linear layer로 구현
Experiments
Datasets
- ImageNet (원본 검증 레이블 및 ReaL 레이블)
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
VTAB
제한된 데이터를 사용하여 다양한 작업으로 전이 학습을 평가하는 벤치마크.
- Natural - 자연스러운 이미지 (예: Pets, CIFAR 등)
- Specialized - 의료 및 위성 이미지
- Structured - 기하학적 이해가 필요한 작업 (예: 로컬라이제이션)
Settings
Models

Training & Fine-tuning
Training
- Adam 옵티마이저: $β_1=0.9, β_2=0.999$
- 초기 훈련에서 빠르고 안정적 수렴
- 데이터 불안정, 손실 함수가 복잡한 초반 학습에서 효과적
- learning rate 초기값에 덜 민감 - batch size: 4096
Fine-tuning
- SGD with momentum
- Adam은 빠르게 수렴하나 optimal 근처에서 overfitting 발생 가능. SGD는 일반화 성능 좋음
- parameter가 대부분 설정되어 있으므로 작은 변화를 세밀히 적용 가능 - batch size: 512
Metrics
downstream dataset에서의 성능
- Few-shot accuracy: 일부 훈련 이미지의 표현을 매핑하여 {−1, 1} 범위의 벡터로 변환하는 정규화된 선형 회귀 문제를 해결하여 평가.
- Fine-tuning accuracy: 해당 데이터셋에서 모델을 미세 조정한 후의 성능.
SOTA와 비교
ViT 모델(ViT-H/14 및 ViT-L/16)을 ResNet 기반 BiT 및 Noisy Student(EfficientNet 기반)와 비교
실험 결과, ViT는 JFT-300M 데이터셋에서 사전 학습 시 ResNet 기반 모델보다 모든 작업에서 더 높은 성능을 보였으며, 더 적은 계산 자원을 사용.
- ImageNet Top-1 정확도: ViT-H/14가 88.55%, BiT-L이 87.54%
- CIFAR-10/100: ViT 모델이 더 높은 성능 기록
- VTAB: 자연 이미지 및 구조적 작업에서 더 우수한 성능
ViT는 JFT-300M과 같은 대규모 데이터셋에서 잘 작동하지만, 데이터셋 크기가 작을 경우 ResNet보다 성능이 떨어지는 경향.
→ ViT가 ResNet에 비해 비전 관련 inductive bias이 적기 때문.
Scaling study
다양한 모델의 사전 학습 비용과 전이 성능 간의 관계를 평가한 결과:
- ViT는 동일한 계산 자원으로 ResNet보다 우수한 성능을 발휘.
- 작은 모델에서는 하이브리드 모델이 ViT보다 약간 우수하지만, 대규모 모델에서는 차이가 사라짐.
- ViT는 더 큰 모델로 확장할수록 성능이 더욱 향상.
ViT internal representation
- 학습된 임베딩 필터의 주요 주성분.
- 첫 번째 레이어에서 입력 이미지 패치를 선형 변환하는 단계
- 이를 분석했을 때 각 패치의 세부 구조를 표현하는 저차원 표현의 기저 함수와 유사한 구조를 가짐
- position embeddings 추가.
- 이미지 내 거리 정보를 position embedding의 유사성으로 인코딩.
- 가까운 패치일 수록 임베딩이 유사.
- attention weight를 기반으로 정보가 통합되는 이미지 공간 내 평균 거리.
- CNN의 receptive field size와 유사.
- self-attention은 가장 낮은 계층에서도 이미지 전역의 정보를 통합할 수 있도록 함.
- 초기 레이어에서 전역적인 정보 통합 능력을 보여줌
- 특정 attention 헤드는 국소적인 정보에 집중함으로써 CNN의 초기 레이어와 유사한 역할 수행
Challenges
- Object Detection, Segmentation 등에 활용
- Self-supervised Learning 탐구 필요.
- 확장성