self-supervised learning 기반 policy pre-training 프레임워크
- visuomotor 기반 자율 주행의 sample inefficiency 문제를 완화
- Large Unlabeled&uncalibrated YouTube 주행 동영상을 활용하여 3D Geometric Scene modeling
- pseudo label을 사용하지 않고 학습.
- 주행과 관련된 visual input만 효과적으로 집중.
Visuomotor Policy Learning
센서에서 얻은 raw data를 입력으로 받아, 적절한 행동을 예측하는 policy 학습 과정
visual perception과 control 모듈을 end-to-end 방식으로 동시에 학습.
- 초기부터 학습하는 것은 어렵고, 방대한 양의 라벨이 있는 데이터나 환경과의 상호작용이 필요
- sample efficiency가 낮아, 학습에 매우 많은 데이터가 필요
- 입력 데이터의 역동성과 가변성이 매우 크기 때문에 view&translation 불변성을 확보하기 어렵다.
Visuomotor driving policy learning
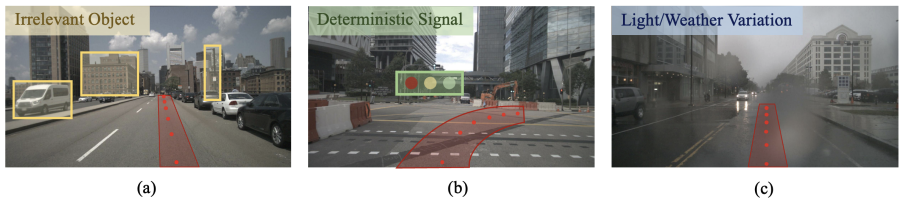
(a) 불필요한 배경 정보 (Static Obstacles & Background)
- 도로 주변의 정적인 물체는 시각적 입력이지만 주행 정책(운전)에 직접적인 영향을 미치지 않음
(b) 결정적이지만 인식이 어려운 정보 (Crucial Yet Hard-to-Recognize Cues)
- 신호등은 운전 제어 출력에 결정적인 영향을 미치지만 매우 작고 배경과 쉽게 구별되지 않음
(c) 조명 및 날씨 변화에 대한 견고성 (Robustness to Light & Weather Conditions)
- 주행 환경은 다양한 조명 및 날씨 조건에서 변화 → 시각적 입력 달라짐
Visual Encoder: 관련 없는 정보 무시 + 중요하지만 작은 물체 효과적 학습 + 변화에 강인
기존 방법의 한계
Pre-training
ImageNet, Contrastive Learning, MIM, Vision-Language Pre-training 등
- 입력 데이터에는 불필요한 정보(노이즈)가 포함됨
- 예: 배경 건물, 멀리 있는 차량, 고정된 장애물 → 운전 결정에는 크게 영향을 주지 않음
- 중요한 정보(traffic signal 등)를 효과적으로 학습해야 함
- 기존 기법 한계: 일반적인 시각적 특성 학습에 초점 → 자율주행에 필요한 Driving Policy 학습 부족
- 복잡한 geometric relationships 고려해야 함
- 다양한 환경에서 강건한 인식이 필요
- view transformation&translation 중요
Pseudo-labeling
- 기존 데이터셋을 활용하여 신뢰도가 낮은 예측값을 레이블로 사용하여 학습하는 방법
- 하지만 모델이 부정확하면 잘못된 라벨이 학습됨 (오차 누적)
- 특히 지리적 차이, 교통 환경 차이(domain gap) 가 클 경우 더욱 취약
- 예: 미국에서 학습된 모델을 한국에서 적용하면, 교통 규칙 차이로 인해 성능 저하
PPGeo: Policy Pre-training via Geometric modeling
PPGeo는 완전한 자율주행을 위한 새로운 사전 학습 기법으로, 기존의 Pseudo-labeling 접근법을 사용하지 않고, 완전히 Self-supervised 방식으로 학습
- 기존 방법과의 차이점:
- 기존 방법: 일반적인 컴퓨터 비전 기법을 활용하여 운전 정책 학습
- PPGeo: 3D 공간 정보를 활용하여 운전 정책을 직접적으로 반영한 특징을 학습
2 Stage Approach
Stage 1: 연속된 프레임을 활용한 geometry 학습
- 두 개의 연속된 이미지(프레임)를 입력으로 사용하여 Depth, Ego-motion, Camera Intrinsics 예측
Stage 2: 단일 프레임 기반 Ego-motion prediction 학습
- 한 개의 이미지(단일 프레임)만을 활용하여 Ego-motion을 예측
- Stage 1에서 학습한 Depth 및 Camera Intrinsics 네트워크를 freeze하고, Visual Encoder를 학습
- visual encoder가 현재 시각적 관찰만을 기반으로 미래의 ego-motion을 예측하고, photometric error를 최적화함으로써 주행 정책 표현을 학습한다.
Visual Encoder는 단일 프레임만 보고도 자율주행과 관련된 핵심 정보(운전 정책 정보)를 추출할 수 있음
Contributions
기존의 사전 학습 방법보다 자율주행에 적합한 정보를 효과적으로 학습하는 방식을 제안
- driving poilcy와 관련된 특징을 효과적으로 학습하기 위해 geometric modeling 활용
Self-supervised learning
- Pseudo-label 없이 완전한 Self-supervised 학습을 실현
- 대규모 데이터에서 Pre-training을 최대로 활용 가능
visual encoder
- 3D 기하학적 모델링을 활용한 Visual Encoder 학습으로 운전 정책 정보 학습 강화
- 단일 프레임 기반 Ego-motion 예측 가능 → 다양한 다운스트림 태스크 적용 용이
성능 개선
- 적은 데이터로도 성능이 2% ~ 100% 이상 향상
- 복잡한 도로 상황에서도 높은 일반화 성능을 보임
Method

- unlabeled 영상에서 self-supervised learning을 통해 2 steps로 visual encoder pre-training
- visual encoder: single-frame input 기반으로 ego-motion을 예측함으로써 driving policy 관련 정보를 효과적으로 인코딩.
- 라벨 없이 이러한 목표를 달성하는 것은 쉽지 않기 때문에, 시각 인코더는 선행 단계(Stage One)의 도움을 받아 학습된다.
- 이러한 방식으로 학습된 시각 인코더는 미세 조정(fine-tuning)하여 다양한 다운스트림 작업(downstream tasks)에 적용할 수 있다 (단계 b, Stage b).
Overview
목표: Visual Encoder $\phi(x)$ pre-train
- raw image input을 주행 의사 결정에 중요한 정보를 포함하는 compact representation으로 변환.
- 표현은 policy $π(\phi(x))$에 의해 활용되어 driving tasks 수행.

Stage 1: Self-supervised Geometric Modeling
Target Image & Source Image
Target Image $I_t$
- 현재 시점 t에서의 기준이 되는 이미지
- 이 이미지를 기반으로 깊이(Depth) 및 자기 운동(Ego-motion)을 예측
- ex) 운전자의 현재 시점에서 보는 이미지
Source Image $I_{t'}$
- Target Image를 복원하기 위해 사용하는 참조 이미지.
- 현재 프레임의 앞뒤 프레임을 사용 $t' \in \{t-1, t+1\}$
- Target Image와 비교하여 깊이 및 ego-motion 정보를 추정하는 데 활용
Self-Supervised Learning
Source Image를 활용한 Target Image 복원을 통해 운전에 필요한 핵심 시각적 특징을 학습하여 강인한(robust) 인코더를 구축
- Source Image에서 Target Image를 잘 재구성하면 모델이 3D 구조와 Ego-motion을 잘 이해한 것임.
학습 목표
- 라벨 없이 대규모 유튜브 운전 영상 학습
- Source Image를 활용해 Target Image를 예측하고 차이를 최소화
- 3D 기하학적 변환(Depth + Pose)을 이용해 Source Image에서 Target Image를 복원
학습 과정: Target Image 재구성을 통해 Depth와 Ego-motion 학습
- Ego-motion 추론 (PoseNet) → 차량의 움직임(6-DoF) 예측
- Depth 정보 학습 (DepthNet) → 도로, 건물, 장애물 등의 깊이 정보 추정
- 다양한 환경에서도 강인한 시각 인코더 학습 (조명, 날씨, 환경 변화에 대응)
Target image $I_t$ 와 연속된 source image $I_{t^{'}}$ 를 입력으로 받아 joint estimation.
- Target image의 depth
- 카메라 내부 intrinsics
- 두 프레임 간 6-DoF ego-motion
이 estimation을 가지고,
- Scene의 3D geometry 모델링
- source image의 pixel을 projecting하여 target image를 reconstruct
Pixel-wise Correspondence
3D geometry를 활용하여 depth와 ego-motion 학습
$\mathbf{p}{t'} = \mathbf{K} \mathbf{T}{t \to t'} \mathbf{D}_t(\mathbf{p}_t) \mathbf{K}^{-1} \mathbf{p}_t,$
- 목표 이미지 $I_t$와 소스 이미지 $I_{t'}$ 간 pixel-wise correspondence
- $\mathbf{p}t$&$\mathbf{p}{t'}$: 각각 $I_t$와 $I_{t'}$의 homogeneous coordinates
- $\mathbf{K}$: predicted camera intrinsic matrix
- $\mathbf{D}_t(\mathbf{p}_t)$ : $I_t$ 내 픽셀 $p_t$의 predicted depth value → DepthNet
- $T_{t \to t'}$: Predicted ego-motion? → PoseNet
이를 통해 target image $I_{t' \to t}$를 $I_{t'}$의 픽셀을 사용하여 재구성할 수 있음.
photometric reconstruction error를 최소화하는 방식으로 최적화 진행.
DepthNet & PoseNet 구조
- DepthNet: encoder-decoder 구조, 입력 이미지의 depth map을 추정
- PoseNet
- 두 개의 이미지를 stack하여 입력한 후,
- 인코더의 bottleneck feature를 이용해
- camera intrinsics
- 자기 운동(ego-motion, 6-DoF)
- 를 각각 예측하는 두 개의 MLP-based heads 사용.
- Camera Intrinsics Estimation
- 광학 중심(optical center) $(c_x, c_y)$
- 초점 거리(focal lengths) $(f_x, f_y)$
- regression을 통해 추정.
연속된 두 프레임 간 변화를 판단하여 ego-motion 추론.
Stage 2: Visuomotor Policy Pre-training
PoseNet을 downstream driving policy learning task를 위해 visual encoder $\phi(x)$로 대체
- stage 1이 끝나면 DepthNet과 PoseNet이 주행 영상 데이터에 적절히 fit된 상태
- 이제 시각 인코더는 단일 프레임 이미지만을 입력으로 받아 ego-motion 예측
- single visual input 기반으로 ego-motion을 예측하는데, 이때 주행 정책 관련 정보를 학습하는 데 집중한다.
Visual Encoder
실제 driving policy 학습
- 연속된 두 프레임 간 ego-motion이 현재 시점의 driving decision or action과 직접적 관련
- $I_t$만을 사용하여 $T_{t \to t+1}$ 예측
- $I_{t-1}$을 사용하여 $T_{t \to t+1}$을 예측한 후, 이를 inverse operation하여 검증
- 최적화: photometric reconstruction error 최소화
- DepthNet & intrinsics estimation: Frozen (backpropagation X)
효과
- 모든 픽셀이 시각 인코더의 학습을 위한 supervision 제공
- 일부 픽셀에서의 깊이 추정 오류가 있더라도, 다른 정확한 픽셀 정보가 이를 보완하여 global optimization 효과를 얻을 수 있음
Visual Encoder vs. poseNet
PoseNet의 pseudo motion label을 활용하여 visual encoder를 직접 supervise.
- 상대적으로 sparse하여 픽셀 단위 supervision 부족
- PoseNet 기반 직접 지도 학습은 noise & prediction inaccuracy 영향을 크게 받을 위험이 있음
결과 및 활용
- 다양한 주행 영상을 통해 driving policy 학습에 필요한 knowledge 습득
- visual encoder의 initial weights: downstream visuomotor 자율 주행 작업에 활용
추가적으로, 대규모 보정되지 않은(uncalibrated) 비디오 데이터에서 학습된 DepthNet과 PoseNet은 depth estimation 및 odometry estimation 작업에도 적용 가능
Loss Function
Photometric Loss
재구성된 이미지 $I_{t' \to t}$와 원본 이미지 $I_t$ 간 차이 최소화
$\ell_{\text{pe}} = \cfrac{\alpha}{2} (1 - \text{SSIM}(I_t, I_{t \to t'})) + (1 - \alpha) \ell_1(I_t, I_{t \to t'}),$
$\text{SSIM}(x, y) = \cfrac{(2\mu_x\mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)}$
Smoothness Loss
depth map이 부드럽게 변화하도록 유도하며 edge 부분에서는 급격한 변화 허용
- depth map이 지나치게 요동치면 모델이 잘못 학습할 수 있음 → 깊이 변화량 줄이는 것이 목적
- depth 변화가 실제로 큰 부분에서는 인식하도록 하기 위해 이 변화량 앞에 $e^{-|\partial_x I_t|}$를 곱함
- 밝기 변화($|\partial_x I_t|$)가 크면 (edge) $e^{-|\partial_x I_t|} \approx 0$ → 깊이 변화 허용
- 밝기 변화($|\partial_y I_t|$)가 작으면 (smooth region) $e^{-|\partial_x I_t|} \approx 1$ → 깊이 변화 억제
$\ell s = |\partial_x d_t^| e^{-|\partial_x I_t|} + |\partial_y d_t^| e^{-|\partial_y I_t|},$
- $d_t^∗$ : 예측된 Depth Map
- $I_t$ : 현재 프레임의 이미지
- $\partial_x, \partial_y$ : x/y 방향(수평/수직)으로 미분
- $|\partial_x d_t^|, |\partial_y d_t^|$ : 깊이 맵의 x/y 방향 변화량 (수평/수직 방향 깊이 변화)
- $|\partial_x I_t|, |\partial_y I_t|$ : 이미지 $I_t$ 의 x/y 방향 변화량 (이미지 경계 검출)
추가로, self-supervised depth estimation을 개선하기 위해 minimum reprojection loss와 auto-masking scheme 추가.
Experiments
데이터셋:
- Unlabeled YouTube Driving video
- 다양한 주행 조건 포함 (지리적 위치, 날씨 변화 등)
- 총 80만 개 프레임 샘플링 (1Hz, 즉 1초당 1프레임)
First Stage:
- 30 epochs
- Optimizer: Adam
- Initial Learning Rate: 10⁻⁴ → 25 epochs 후 10⁻⁵로 감소
Second Stage (Encoder Training):
- 20 epochs
- Optimizer: AdamW
- Cyclic Learning Rate Scheduler: 10⁻⁶ ~ 10⁻⁴ 사이에서 변동
공통 설정:
- Batch Size: 128
- Data Augmentation: ColorJitter/ RandomGrayScale / GaussianBlur
Baselines
- Random: Kaiming Initialization
- ImageNet: ImageNet 데이터셋 (Deng et al., 2009)으로 사전 학습된 모델 사용
- MIM (Masked Image Modeling): SimMIM (Xie et al., 2022) 방법 사용 (랜덤 패치 마스킹 후 복원)
- MoCo: MoCo-v2 (Chen et al., 2020c) 사용하여 YouTube 주행 영상에서 대조 학습
- ACO: Action-Conditioned Contrastive Learning (Zhang et al., 2022b) 방법 사용
- Steering Angle을 기반으로 MoCo-v2 위에 추가 학습 진행
- SelfD: 단순한 사전 학습이 아니라, 각 태스크별 정책 모델을 학습하여 비교
- Task 데이터 → YouTube 데이터 (Pseudo Label) → Task 데이터 Fine-Tuning 순으로 학습
Downstream Autonomous Driving Tasks
- CARLA 환경에서 3가지 imitation learning 기반 closed-loop 주행
- CARLA 환경에서 1가지 reinforcement learning 기반 task
- nuScenes 데이터셋을 활용한 1가지 open-loop 계획

1) Imitation Learning 기반 주행 태스크 (CARLA)
- Navigation (기본 네비게이션)
- CoRL2017 benchmark 기반
- Town01에서 훈련, Town02에서 테스트 (새로운 날씨 환경 적용)
- 4K~40K개의 훈련 데이터 사용
- 평가 지표: Success Rate

- Navigation Dynamic
- Navigation 태스크와 동일하지만 다른 차량 및 동적 객체가 존재하는 환경에서 평가

- Leaderboard Town05-long (CARLA LeaderBoard)
- Town01, 03, 04, 06에서 학습 후 Town05에서 평가 (보지 못한 환경에서 테스트)
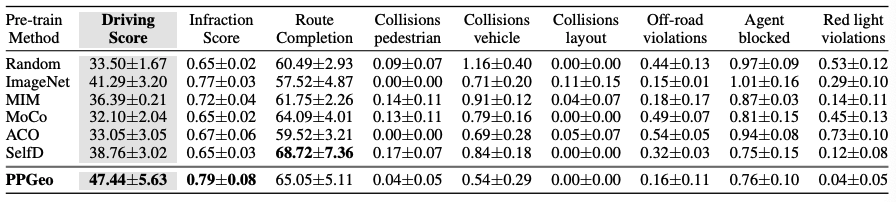
- ACO는 Steering Angle 정보만 학습했기 때문에, 복잡한 환경에서 성능이 낮음
- 평가 지표: Driving Score = Route Completion × Infraction Score
2) 강화 학습 기반 주행 태스크 (CARLA)
- Proximal Policy Optimization (PPO) 기반 강화 학습
- CILRS 모델을 PPO 알고리즘으로 학습
- pre-train된 인코더를 freeze하여, 사전 학습된 표현 학습이 강화 학습 성능에 미치는 영향을 분석
3) nuScenes 기반 경로 계획 (Planning)
- 실제 주행 데이터 기반의 Trajectory Planning 실험
- 3초 후의 차량 궤적을 예측 (0.5Hz 샘플링)
- 평가 지표:
- GT (Ground Truth) 궤적과의 비교 (예측 정확도)
- Collision Rate (충돌 비율)
3) 강화 학습 기반 실험 (PPO)
- 사전 학습된 인코더를 Freeze(동결) 한 경우에도 PPGeo가 우수한 성능을 유지
- 즉, PPGeo가 더 나은 특징 표현(Feature Representation)을 학습하고 있음을 증명
4) nuScenes Trajectory Planning
- PPGeo 기반 경로 계획 모델이 가장 낮은 충돌률을 기록
- 이는 PPGeo가 실제 도로 데이터에서도 효과적인 사전 학습 방법임을 의미

Depth and Odometry Estimation
PPGeo의 stage 1 학습이 Depth Estimation & Odometry Estimation에도 효과적인지 검증
- DepthNet과 PoseNet을 PPGeo stage 1 학습 이후 초기 가중치로 사용해 Monodepthv2 학습
- KITTI 데이터셋 사용
- 대규모 비지도 주행 데이터로 사전 학습하면 Depth&Odometry Estimation 성능 향상

Visualization Results
Eigen-CAM 사용한 특징 맵 시각화

- 다른 사전 학습 방법과 비교하여 PPGeo가 주목하는 영역을 분석
- PPGeo의 특징:
- 차선 및 전방 도로에 집중 (주행과 직접적으로 관련된 영역)
- 브레이크 원인을 잘 포착 (앞 차량, 신호등 등)
- ImageNet 사전 학습 모델과 비교:
- ImageNet 모델은 주행과 무관한 영역에 집중할 수도 있음
- 예: 불필요한 물체에 초점을 맞추는 경우 (Row 2&3)
3.6 Ablative Study
PPGeo의 각 요소가 실제 성능에 미치는 영향
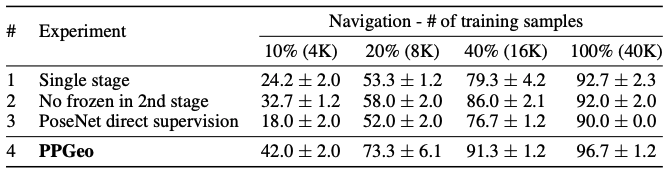
- DepthNet과 시각 인코더를 한 번에 동시에 학습
- 깊이 추정과 자율주행 인코딩을 동시에 학습하면 Ego-motion 학습이 어려움
- 2단계 학습에서 DepthNet을 동시 학습 (Freeze X)
- 2단계에서 DepthNet을 추가로 업데이트하면 깊이 추정 품질이 저하되고 주행 성능에도 악영향
- 1단계 PoseNet을 이용해 Pseudo Label 생성 → 직접 지도 학습
- 부정확한 Pseudo Label은 오히려 학습을 방해하여 성능을 떨어뜨림