Language-guided Closed-loop End-to-end Driving Framework
- Multi-modal sensor data를 natural language instruction과 통합하여 처리
- 인간 및 내비게이션 소프트웨어와의 상호작용이 가능한 현실적인 지시 환경을 구현
- 64,000개의 instuction 수행 데이터 클립을 포함한 공개 데이터셋 & LangAuto 벤치마크를 함께 제공

LLM models for Autonomous Driving
자연어를 이해할 수 있다면 복잡한 환경에서의 고급 추론과 인간과의 효율적인 상호작용 가능.
- 복잡한 도심 환경 및 돌발 상황 대처
- 복잡한&돌발 상황 어려움 → 승객이나 내비게이션의 지시를 따라 보다 쉽게 해결. - Instruction 반영
- 작은 물체 감지 한계 → 승객이 직접 지시를 내릴 수 있어 보다 유연한 대응 가능
기존 연구의 한계
LLM-Driver, DriveLM, GPT-Driver, LanguageMPC 등
- LLM이 센서 데이터 및 내비게이션 명령을 텍스트 설명으로 변환
- 텍스트를 LLM에 입력하여 주행 결정을 생성
- 텍스트 기반 주행 결정을 실행 가능한 제어 명령으로 변환
한계:
- 서로 다른 LLM이 개별 작업을 수행하기 때문에 end-to-end 학습이 어렵다.
- 대규모 데이터와 확장성에 한계가 있다.
- 센서 데이터의 오류에 취약
LMDrive
이는 자연어 기반 지시를 따르는 멀티모달 LLM 모델로, end-to-end closed-loop 자율 주행을 구현
기능 수행:
- 카메라-라이다(CAMERA-LiDAR) 센서 데이터를 입력받음
- 자연어 기반 내비게이션 및 주행 지시를 이해함
- 직접 차량 제어 신호를 생성하여 실시간 주행 수행
적용:
- 사전 학습된 LLM을 freeze하여 기존의 추론 능력을 보존
- 카메라-라이다 데이터 인코더 및 학습 가능한 입출력 어댑터 적용
- 주행 태스크에 특화된 사전 학습 전략 도입
Contributions
- 엔드 투 엔드 폐쇄 루프 언어 기반 자율 주행 프레임워크 LMDrive를 제안
- 멀티모달 센서 데이터와 자연어 명령을 활용하여 실시간 주행 가능 - 64K 데이터 클립을 포함한 주행 데이터셋 구축
- 클립당 내비게이션 지시, 보조 지시, 멀티모달 센서 데이터 및 제어 신호 포함 - LangAuto 벤치마크 제공
- 잘못된/복잡한 지시 포함 및 도전적인 주행 시나리오 반영 - 광범위한 폐쇄 루프 실험을 통해 프레임워크의 효과 검증
- LMDrive의 성능 분석 및 추가 연구를 위한 insight 제공
Dataset Generation
Intelligent Driving Agent를 개발하여 세 가지 입력을 기반으로 driving action 생성
- Multi-view Camera&LiDAR: 현재 Scene을 인식하고 준수하는 행동 생성.
- Navigation Instructions: 차선 변경, 회전 등 자연어 명령 기반 주행.
- 인간 또는 네비게이션 소프트웨어의 지시를 이해하고 수행. - Human Notice Instruction: 사용자와 상호작용하며 선호도에 맞게 적응.
- adversarial events, long-tail events 대처 가능.
- CARLA Simulator: 실제와 유사한 동적 폐쇄 루프 환경을 시뮬레이션.
- 두 단계로 데이터 수집 진행
- 전문가 에이전트(Expert Agent)로 센서 및 제어 데이터 수집.
- 수집된 데이터를 네비게이션 및 사용자 지시와 매칭하여 라벨링.
Sensor and Control data collection
- Rule-based Expert Agent 활용.
- 약 300만(3M) 주행 프레임 데이터 생성.
- 8개 Towns, 2.5K개 Routes, 21가지 환경 조건(날씨, 시간대 포함)에서 실행.
- 센서 구성
- RGB 카메라 4대 (좌측, 전면, 우측, 후면).
- LiDAR 1대 (64채널, 초당 60만 개 포인트 생성).
- 측면 카메라는 각각 60° 기울어짐.
- 전면 이미지는 center-crop하여 원거리 신호등 상태 감지용 Focus-view 생성.
Parsing and language annotation
수집된 데이터 → 개별 주행 Clip으로 parsing&labeling
- 각 클립은 하나의 Navigation Instruction과 연관됨.

- 예: 프레임 T0에서 좌회전 시작 → 프레임 Tn에서 완료
- $(T_0, T_n)$ 구간을 "다음 교차로에서 좌회전하세요"로 라벨링.
Adversarial Event 발생 시 Notice Instruction 추가

- Ex) 돌발 상황이 프레임 Ta에서 발생 → 승객이나 보조 시스템이 경고 메시지를 제공
- 결과적으로, 각 클립에는 다음 요소 포함
- 센서 데이터, 제어 신호, 네비게이션 명령, 선택적 Notice Instruction.
- 데이터 규모:
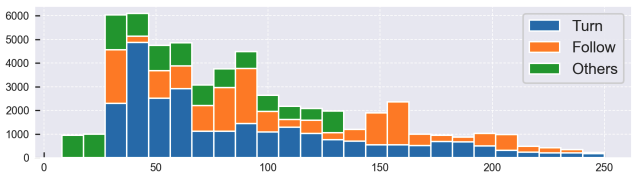
- 64K(64,000)개의 Clip
- 464K(464,000)개의 Notice Instruction
Instruction design
- 3가지 네비게이션 명령 유형: Follow / Turn / Others
- 1가지 Notice Instruction 유형 포함
- 총 56가지 명령어(Instruction) 사용
Realistic instructional settings
- Diversifying the Instructions - 동일한 의미라도 다양한 표현 방식 적용.
- ChatGPT API를 활용하여 각 instruction 유형당 8개 변형 생성.
- Incorporating Misleading Instructions - 오류 명령을 포함하여 모델의 Robustness 향상.
- Ex) 단일 차선 도로에서 “Change to left lane” 명령은 위험.
- Connecting Multiple Instructions - 다중 명령 수행 가능하도록 데이터 구성.
- “Turn right at this intersection, then go straight to the next intersection and turn right again.

Instruction design
- 3가지 네비게이션 명령 유형: Follow / Turn / Others
- 1가지 Notice Instruction 유형 포함
- 총 56가지 명령어(Instruction) 사용
Realistic instructional settings
- Diversifying the Instructions - 동일한 의미라도 다양한 표현 방식 적용.
- ChatGPT API를 활용하여 각 instruction 유형당 8개 변형 생성.
- Incorporating Misleading Instructions - 오류 명령을 포함하여 모델의 Robustness 향상.
- Ex) 단일 차선 도로에서 “Change to left lane” 명령은 위험.
- Connecting Multiple Instructions - 다중 명령 수행 가능하도록 데이터 구성.
- “Turn right at this intersection, then go straight to the next intersection and turn right again.
Methodology
Vision Encoder
multi-view&multi-modality를 설계하여 센서 데이터를 encoding&fusion → visual token 생성

- sensor encoding 모듈: 이미지 및 LiDAR 입력을 각각 인코딩한다.
- BEV decoder: image &point cloud feature을 융합하여 visual tokens을 생성 → 언어 모델로 전달
- prediction heads: perception 태스크에 pre-training → LLM 결합을 위해 encoder의 weight는 frozen
Sensor Encoding
이미지 입력:
- 2D Backbone: ResNet - image feature map 추출
- 1차원 flattened tokens으로 변환.
- 여러 개의 view에서 얻은 토큰을 융합(fuse)하여 global context를 포괄적으로 이해할 수 있도록 한다.
- 이를 위해, $K_{enc} = 1$개의 Transformer encoder layer 적용.
- 각 레이어는 Multi-Headed Self-Attention, MLP block, Layer Normalization 포함.
LiDAR 입력:
- 3D Backbone: PointPillars - raw point cloud 데이터 처리
- 각 pillar: 0.25m × 0.25m 범위 내의 포인트를 포함하며, ego-centered LiDAR features 생성
- PointNet 사용하여 feature aggregate & downsample C×H×W 크기의 feature map 생성
- 이후 BEV query로 사용.
BEV Decoder
- encoding된 sensor features을 BEV decoder에 전달하여 visual tokens 생성
- $K_{dec} = 3$ 개의 표준 Transformer 레이어로 설계.
- BEV point cloud features: H × W 크기의 queries로 BEV 디코더에 입력
- multi-view image feature와 상호작용(attend)하여 BEV tokens 생성.
- N개의 learnable queries를 BEV 디코더에 추가하여 N개의 waypoint 토큰을 생성하고,
- 1개의 학습 가능한 쿼리를 추가하여 traffic light token 생성.
- 세 가지 유형의 시각 토큰(BEV, waypoints, traffic lights)을 LLM)에 입력
세부사항
- ResNet의 5번째 스테이지를 feature map으로 사용.
- 이후, MLP 레이어를 적용하여 해당 차원을 Q-Former의 입력 차원과 동일하도록 768로 변환
- LiDAR Point Cloud Data 인코딩을 위해 PointNet 단순화 버전 사용.
- Q-Former로 입력되는 시각 토큰(Visual Tokens) 구성
- 400개의 BEV 토큰
- 5개의 미래 웨이포인트(Future Waypoint) 토큰
- 1개의 교통 신호(Traffic Light) 토큰
LLM for instruction-following auto driving
Tokenizer, Q-Former, Adapters를 통해 시각 토큰과 언어 지시를 입력받아 제어 신호를 예측하고, 주어진 지시가 완료되었는지 판단한다.
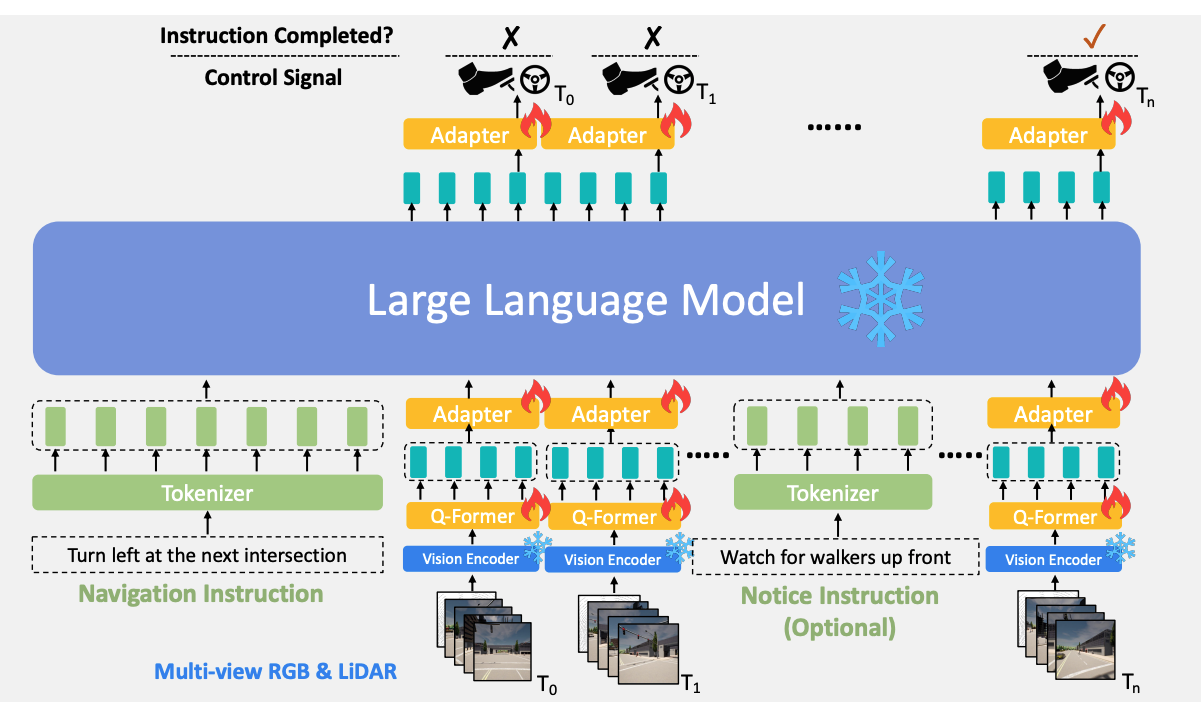
LLaMA 사용
- LLM은 frozen된 Vision Encoder가 생성한 센서 토큰을 처리
- 자연어 지시를 이해, 필요한 control signal 생성, 주어진 지시가 완료되었는지 예측
구성요소 추가
- LLM과 instruction, visual input, action prediction 간의 연결을 위해.
- Tokenizer
- Q-Former
- 어댑터(Adapters) 두 개
Instruction and Visual Tokenization
- navigation instruction & optional notice instruction이 주어지면, LLaMA tokenizer를 사용하여 textual tokens으로 변환한다.
- cumulative error 줄이고 temporal consistency 높이기 위해, $T_{max}$ 개의 과거 센서 정보를 활용
- 각 프레임의 multi-view 및 multi-modality 센서 입력을 처리
- 사전 학습된 비전 인코더를 사용하여 visual tokens 생성.
- H × W 크기의 BEV 토큰
- N개의 waypoint 토큰
- 1개의 traffic light 토큰
- Visual Token을 줄이기 위해, BLIP-2의 Q-Former를 사용
- BLIP-2의 모델 아키텍처 및 pre-trained weights 활용.
- M개의 learnable queries를 사용하여 visual token을 cross-attention layer 통해 압축.
- 각 프레임의 visual token 수를 M개로 감소.
- 2-layer MLP Adapter: Q-Former가 생성한 토큰을 LLM 언어 토큰과 동일한 차원으로 변환&입력
Action Prediction
- instruction & visual token의 sequence를 바탕으로 action tokens 예측
- 2-layer MLP 어댑터를 사용하여 미래 waypoints 예측, 주어진 지시가 완료되었는지 나타내는 flag를 출력
- Training: 각 과거 프레임에 대한 예측을 수행하여 supervision signal를 강화
- inference: 최신 프레임에 대한 예측만 실행
- control signal 생성하기 위해 LBC 방식을 따라 두 개의 PID 컨트롤러 활용.
- 가로 방향(latitudinal) 제어: 차량의 진행 방향을 조정
- 세로 방향(longitudinal) 제어: 차량의 속도를 조정
Training Objectives
LLM 및 관련 구성 요소를 finetuning할 때, 두 가지 loss terms 사용.
- L1 Waypoint Loss
- 분류 손실(Classification Loss, Cross-Entropy): 현재 프레임이 주어진 지시를 완료했는지 여부를 판별
Training Details
1) Vision Encoder Pre-training Stage
- 비전 인코더만 single frame의 센서 데이터를 입력으로 받아 학습.
- 학습 데이터셋은 섹션 3에서 수집된 데이터를 활용한다.
- Instruction annotation 과정에서 일부 프레임이 제거될 수 있어 raw dataset의 약 300만 개(3M frames) 프레임 데이터를 사용하여 사전 학습.
- Prediction Headers: Object Detection, Traffic Light Status Classification, Future Waypoint Prediction pre-training
Settings
- AdamW optimizer + Cosine Learning Rate Scheduler
- Learning Rate
- Transformer Encoder & 3D Backbone: $\frac{\text{BatchSize}}{512} \times 5e^{-4}$
- 2D Backbone: $\frac{\text{BatchSize}}{512} \times 2e^{-4}$
- 총 35 에포크(epoch) 학습, 초기 5 에포크는 웜업(Warm-up).
- Augmentation: RGB 이미지에 random scaling(0.9~1.1) & Color Jittering
2) Instruction-finetuning Stage
- Q-Former&Adapters만 학습
- sequence of frames 입력, 훈련 시에는 고정된 Tmax 시퀀스 길이를 설정하여 batch 데이터 구성.
- instruction-following 데이터 사용.
- vision encoder:
- freeze & prediction headers 제거
- visual token을 생성하여 LLM에 입력하는 역할 수행
Settings
- Cosine Learning Rate Scheduler
- Batch Size = 32일 때, Learning Rate = $e^{-4}$
- 총 15 epoch 학습, 초기 2000 iteration 동안 Warm-up 적용.
- Weight Decay = 0.07 설정.
- 최대 기록 가능한 과거 프레임 수 (Maximum Historic Horizon, TmaxT_{\text{max}}Tmax) = 40
- 데이터 클립이 40 프레임을 초과하면 최근 40 프레임만 유지하여 학습.
Misleading Instructions 학습
- 잘못된 지시를 거부할 수 있도록.
- 잘못된 지시가 주어진 후 약 1초 뒤 해당 데이터를 ‘completed’로 레이블링.
Temporal data sampling & augmentation
- 데이터 수집 frequency는 약 10Hz로, 인접한 프레임들의 데이터가 매우 유사할 가능성이 크다.
- video prediction 기법을 참고하여, fixed interval로 훈련 프레임 샘플링
- temporal augmentation을 적용하여,
- 훈련 프레임 random shift
- 이동 범위는 고정된 샘플링 간격보다 작도록 설정하여 모델 일반화 향상.

첫번째&두번째: 모델이 각각의 지시에 따라 다른 웨이포인트를 예측.
세 번째: 잘못된 지시. 적절히 거부하여 속도를 줄이고 상황에 맞는 안전한 경로를 생성.
LangAuto Benchmark
Language-guided Instructions을 사용한 자율 주행 성능 평가 CARLA 벤치마크
기존 CARLA 벤치마크: Discrete Driving Commands 또는 Target Waypoints 통해 주행 유도.
오직 Natural Language Navigation Instructions & 선택적 Notice Instructions만 제공.
- 8개 CARLA Town
- 7 Weather Conditions: Clear, Cloudy, Wet, MidRain, WetCloudy, HardRain, SoftRain.
- 3 Time Conditions: Night, Noon, Sunset.
LangAuto track
- 주어진 Route에 따라 Navigation Instructions 제공.
- 차량의 현재 위치에 따라 지침이 업데이트됨.
- 경로 길이에 따라 Sub-tracks으로 나뉨:
- LangAuto: 500m 이상 긴 경로.
- LangAuto-Short: 150m~500m 중간 길이 경로.
- LangAuto-Tiny: 150m 이하의 짧은 경로.
LangAuto-Notice track
- LangAuto track에 추가적으로 Notice Instructions를 제공.
- 현실에서 승객이나 보조 시스템이 제공하는 긴급 상황 알림을 시뮬레이션.
- long-trail complex or adversarial scenarios에서 발생
- adversarial events 발생 시 공지(notice instructions) 제공
- AI 에이전트가 공지 정보를 실시간으로 활용하여 충돌 및 교통법규 위반 감소 (안전성 향상).
LangAuto-Sequential track
- LangAuto 트랙을 기반으로 10%의 연속된 2~3개의 지시문을 하나로 합침.
- 현실적인 다중 문장 네비게이션 시나리오를 반영.
Misleading Instructions
- AI가 잘못된 지침을 따르지 않고 안전한 판단을 내리는지를 테스트.
- 약 5%의 확률로 1~2초 동안 잘못된 지시문이 제공됨.
Metrics
- Route Completion (RC): 전체 경로 길이 중 완료된 비율을 나타냅니다.
- Infraction Score (IS): 에이전트가 발생시킨 위반 사항(충돌 또는 교통 법규 위반)을 측정.
- Driving Score (DS): RC와 IS의 곱으로, 주행 진행 상황과 안전성을 종합적으로 평가
Experiments
LangAuto 벤치마크에서 제안된 방법을 CARLA 시뮬레이터(버전 0.9.10.1)에서 구현&평가
LLM Backbones

- 사전 학습된 멀티모달 LLM을 활용하는 것이 자율주행에서 중요함.
- 인스트럭션 파인튜닝이 성능 향상에 기여
- 랜덤 초기화된 7B LLM 모델은 훈련 데이터가 같아도 제대로 주행하지 못함 → 사전 학습 및 파인튜닝의 필요성 증명.
Module Design

- Q-Former 제거: BEV 토큰 수를 줄이지 않고 4×4로 다운샘플링 - Driving Score 36.2 → 31.7
- BEV 토큰 미사용: 장애물 및 도로 구조 인식이 어려워져 Infraction Score 0.81 → 0.72
- 비전 인코더 사전 학습 미실시: 성능 크게 하락 Driving Score: 16.9 → 비전 인코더 사전 학습 필수
LangAuto-Notice Benchmark

LangAuto-Sequential Benchmark
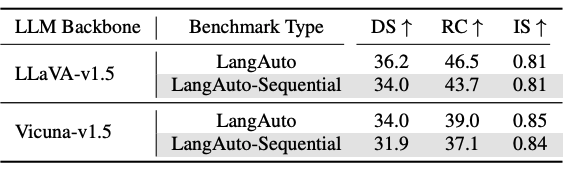
- AI 에이전트가 완료된 지시와 미완료 지시를 구별해야 하는 추가적인 시간적 인식 능력 필요
- LLaVA 및 Vicuna 기반 모델 모두 Driving Score & Route Completion 감소